Summary: in this tutorial, you’ll learn how to use Django Group By with aggregate functions to calculate aggregation for groups.
Introduction to the Django Group By #
The SQL GROUP BY clause groups the rows returned by a query into groups. Typically, you use aggregate functions like count, min, max, avg, and sum with the GROUP BY clause to return an aggregated value for each group.
Here’s the basic usage of the GROUP BY clause in a SELECT statement:
SELECT column_1, AGGREGATE(column_2)
FROM table_name
GROUP BY column1;Code language: SQL (Structured Query Language) (sql)In Django, you can you the annotate() method with the values() to apply the aggregation on groups like this:
(Entity.objects
.values('column_2')
.annotate(value=AGGREGATE('column_1'))
)Code language: Python (python)In this syntax;
values('column_2')– pass the column that you want to group to thevalues()method.annotate(value=AGGREGATE('column_1'))– specify what to aggregate in theannotate()method.
Notice that the order of calling values() and annotates() matter. If you do not call the values() method first and annotate() second, the expression won’t produce aggregate results.
Django Group By examples #
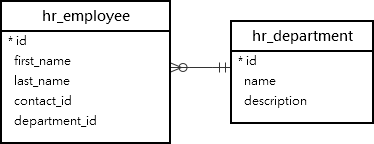
We’ll use the Employee and Department models from the HR application for the demonstration. The Emloyee and Department models map to the hr_employee and hr_department tables in the database:
1) Django Group By with Count example #
The following example uses the values() and annotate() method to get the number of employees by department:
>>> (Employee.objects
... .values('department')
... .annotate(head_count=Count('department'))
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
COUNT("hr_employee"."department_id") AS "head_count"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.001492s [Database: default]
<QuerySet [{'department': 1, 'head_count': 30}, {'department': 2, 'head_count': 40}, {'department': 3, 'head_count': 28}, {'department': 4, 'head_count': 29}, {'department': 5, 'head_count': 29}, {'department': 6, 'head_count': 30}, {'department': 7, 'head_count': 34}]>Code language: Python (python)How it works.
First, group the employees by department using the values() method:
values('department')Code language: Python (python)Second, apply the Count() to each group:
annotate(head_count=Count('department'))Code language: Python (python)Third, sort the objects in the QuerySet by department:
order_by('department')Code language: Python (python)Behind the scenes, Django executes the SELECT statement with the GROUP BY clause:
SELECT "hr_employee"."department_id",
COUNT("hr_employee"."department_id") AS "head_count"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Code language: SQL (Structured Query Language) (sql)2) Django Group By with Sum example #
Similarly, you can use the Sum() aggregate to calculate the total salary of employees in each department:
>>> (Employee.objects
... .values('department')
... .annotate(total_salary=Sum('salary'))
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
SUM("hr_employee"."salary") AS "total_salary"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.000927s [Database: default]
<QuerySet [{'department': 1, 'total_salary': Decimal('3615341.00')}, {'department': 2, 'total_salary': Decimal('5141611.00')}, {'department': 3, 'total_salary': Decimal('3728988.00')}, {'department': 4, 'total_salary': Decimal('3955669.00')}, {'department': 5, 'total_salary': Decimal('4385784.00')}, {'department': 6, 'total_salary': Decimal('4735927.00')}, {'department': 7, 'total_salary': Decimal('4598788.00')}]>
Code language: Python (python)3) Django Group By with Min, Max, and Avg example #
The following example applies multiple aggregate functions to groups to get the lowest, average, and highest salary of employees in each department:
>>> (Employee.objects
... .values('department')
... .annotate(
... min_salary=Min('salary'),
... max_salary=Max('salary'),
... avg_salary=Avg('salary')
... )
... .order_by('department')
... )
SELECT "hr_employee"."department_id",
MIN("hr_employee"."salary") AS "min_salary",
MAX("hr_employee"."salary") AS "max_salary",
AVG("hr_employee"."salary") AS "avg_salary"
FROM "hr_employee"
GROUP BY "hr_employee"."department_id"
ORDER BY "hr_employee"."department_id" ASC
LIMIT 21
Execution time: 0.001670s [Database: default]
<QuerySet [{'department': 1, 'min_salary': Decimal('45427.00'), 'max_salary': Decimal('149830.00'), 'avg_salary': Decimal('120511.366666666667')}, {'department':
2, 'min_salary': Decimal('46637.00'), 'max_salary': Decimal('243462.00'), 'avg_salary': Decimal('128540.275000000000')}, {'department': 3, 'min_salary': Decimal('40762.00'), 'max_salary': Decimal('248265.00'), 'avg_salary': Decimal('133178.142857142857')}, {'department': 4, 'min_salary': Decimal('43000.00'), 'max_salary':
Decimal('238016.00'), 'avg_salary': Decimal('136402.379310344828')}, {'department': 5, 'min_salary': Decimal('42080.00'), 'max_salary': Decimal('246403.00'), 'avg_salary': Decimal('151233.931034482759')}, {'department': 6, 'min_salary': Decimal('58356.00'), 'max_salary': Decimal('248312.00'), 'avg_salary': Decimal('157864.233333333333')}, {'department': 7, 'min_salary': Decimal('40543.00'), 'max_salary': Decimal('238892.00'), 'avg_salary': Decimal('135258.470588235294')}]>Code language: Python (python)4) Django group by with join example #
The following example uses the values() and annotate() methods to get the number of employees per department:
>>> (Department.objects
... .values('name')
... .annotate(
... head_count=Count('employee')
... )
... )
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON ("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
LIMIT 21
Execution time: 0.001953s [Database: default]
<QuerySet [{'name': 'Marketing', 'head_count': 28}, {'name': 'Finance', 'head_count': 29}, {'name': 'SCM', 'head_count': 29}, {'name': 'GA', 'head_count': 30}, {'name': 'Sales', 'head_count': 40}, {'name': 'IT', 'head_count': 30}, {'name': 'HR', 'head_count': 34}]>Code language: Python (python)How it works.
values('name')– groups department by name.annotate(headcount=Count('employee'))– counts employees in each department.
Behind the scenes, Django uses a LEFT JOIN to join the hr_department table with hr_employee table and apply the COUNT() function to each group.
Django group by with having #
To apply a condition to the groups, you use the filter() method. For example, the following uses the filter() method to get the department with head counts are more than 30:
>>> (Department.objects
... .values('name')
... .annotate(
... head_count=Count('employee')
... )
... .filter(head_count__gt=30)
... )
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON ("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
HAVING COUNT("hr_employee"."id") > 30
LIMIT 21
Execution time: 0.002893s [Database: default]
<QuerySet [{'name': 'Sales', 'head_count': 40}, {'name': 'HR', 'head_count': 34}]>
Code language: Python (python)Behind the scenes, Django uses the HAVING clause to filter the group based on the condition that we pass to the filter() method:
SELECT "hr_department"."name",
COUNT("hr_employee"."id") AS "head_count"
FROM "hr_department"
LEFT OUTER JOIN "hr_employee"
ON ("hr_department"."id" = "hr_employee"."department_id")
GROUP BY "hr_department"."name"
HAVING COUNT("hr_employee"."id") > 30
Code language: Python (python)Summary #
- Use
values()andannotate()method to group rows into groups. - Use
filter()to add conditions to filter groups.